Domain Adaptation Knowledge Distillation

Figure 1 From Domain Adaptation Of Dnn Acoustic Models Using Knowledge Distillation Semantic Scholar
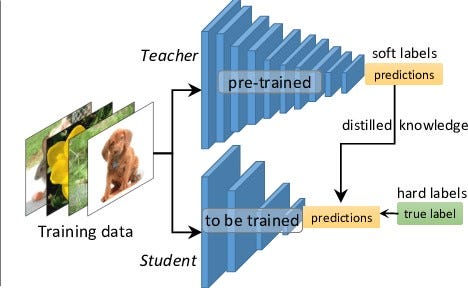
Knowledge Distillation Chrisai
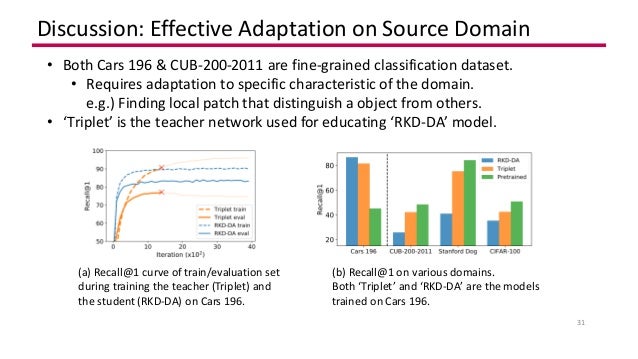
Relational Knowledge Distillation

Socionext And Osaka University Develop New Deep Learning Method For Object Detection In Low Light Conditions

Fast Generalized Distillation For Semi Supervised Domain Adaptation Semantic Scholar
About Mohammad Havaei Personal Page
Knowledge distillation for bert unsupervised domain adaptation.
Domain adaptation knowledge distillation. A pre trained language model bert has brought significant performance improvements across a range of natural language processing tasks. Our contributions are four fold. To fill this gap we propose knowledge adaptation an extension of knowledge distillation bucilua et al 2006. Meng zhong et al.
Li kunpeng et. Cluster alignment with a teacher for unsupervised domain adaptation. 10 22 2020 by minho ryu et al. In future work we will consider combining the adversarial approaches with knowledge distillation to improve the generalisability of dnns across domains without the need for large annotated datasets.
Introduction deep learning dl models and in particular convolutional neural networks cnns can achieve state of the art perfor mance in a wide range of visual recognition applications such as classification object detection and semantic segmentation 1 3. We observed that the mean dice overlap improved from 0 65 0 69. Hinton et al 2015 to the domain adaptation scenario. Attention bridging network for knowledge transfer.
Knowledge distillation for semi supervised domain adaptation. Meng zhong et al. Cluster alignment with a teacher for unsupervised domain adaptation. Domain adaptation using ada as a teacher and then trained a student based on it.
5 share. In the absence of sufficient data variation e g scanner and protocol variability in annotated data deep neural networks dnns tend to overfit during training. Despite its great. 08 16 2019 by mauricio orbes arteaga et al.
A pre trained language model bert has brought significant performance improvements across a range of natural language processing tasks. Knowledge distillation for semi supervised domain adaptation. Domain adaptation via teacher student learning for end to end speech recognition. Since the model is trained on a large corpus of diverse topics it shows robust performance for domain shift problems in which data distributions at training source data and testing target data differ while sharing similarities.
Domain adaptation knowledge distillation visual recognition. Knowledge distillation for semi supervised domain adaptation. Domain adaptation via teacher student learning for end to end speech recognition. Ieee international conference on acoustics speech and signal processing.
We propose an end to end trainable framework for learning compact multi class object detection models through knowledge distillation section3 1. Attention bridging network for knowledge transfer. Since the model is trained on a large corpus of diverse topics it shows robust performance for domain shift problems in which data. Proceedings of the 12th acm sigkdd international conference on knowledge discovery and data.
We show how a student model achieves state of the art results on unsu pervised domain adaptation from multiple sources on a standard sentiment anal. 1 share.
Http Ecai2020 Eu Papers 405 Paper Pdf
Http Openaccess Thecvf Com Content Cvpr 2019 Papers Park Relational Knowledge Distillation Cvpr 2019 Paper Pdf
Ziwei Liu S Homepage
Https Arxiv Org Pdf 2007 10787
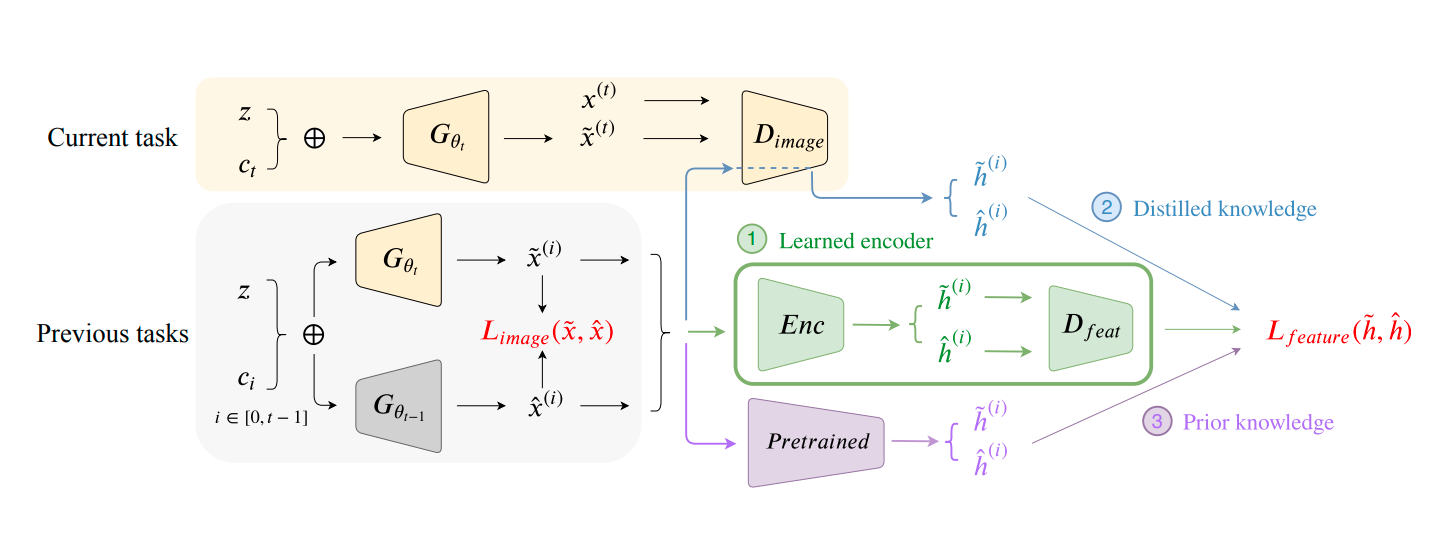
Learning An Evolutionary Embedding Via Massive Knowledge Distillation Springerlink

Cvpr2019 Structural Knowledge Distillation For Semantic Segmentation Programmer Sought

Knowledge Distillation And Student Teacher Learning For Visual Intelligence A Review And New Outlooks

Pdf Knowledge Distillation And Student Teacher Learning For Visual Intelligence A Review And New Outlooks
Https Arxiv Org Pdf 1809 01921
Http Cvlab Postech Ac Kr Lab Papers 1500 Pdf
