Domain Adaptation Reinforcement Learning

Deepmind Releases Acme A Library Of Reinforcement Learning Components And Agents Artificialintelligence Machinelearning In 2020 Reinforcement Learning Deep Learning
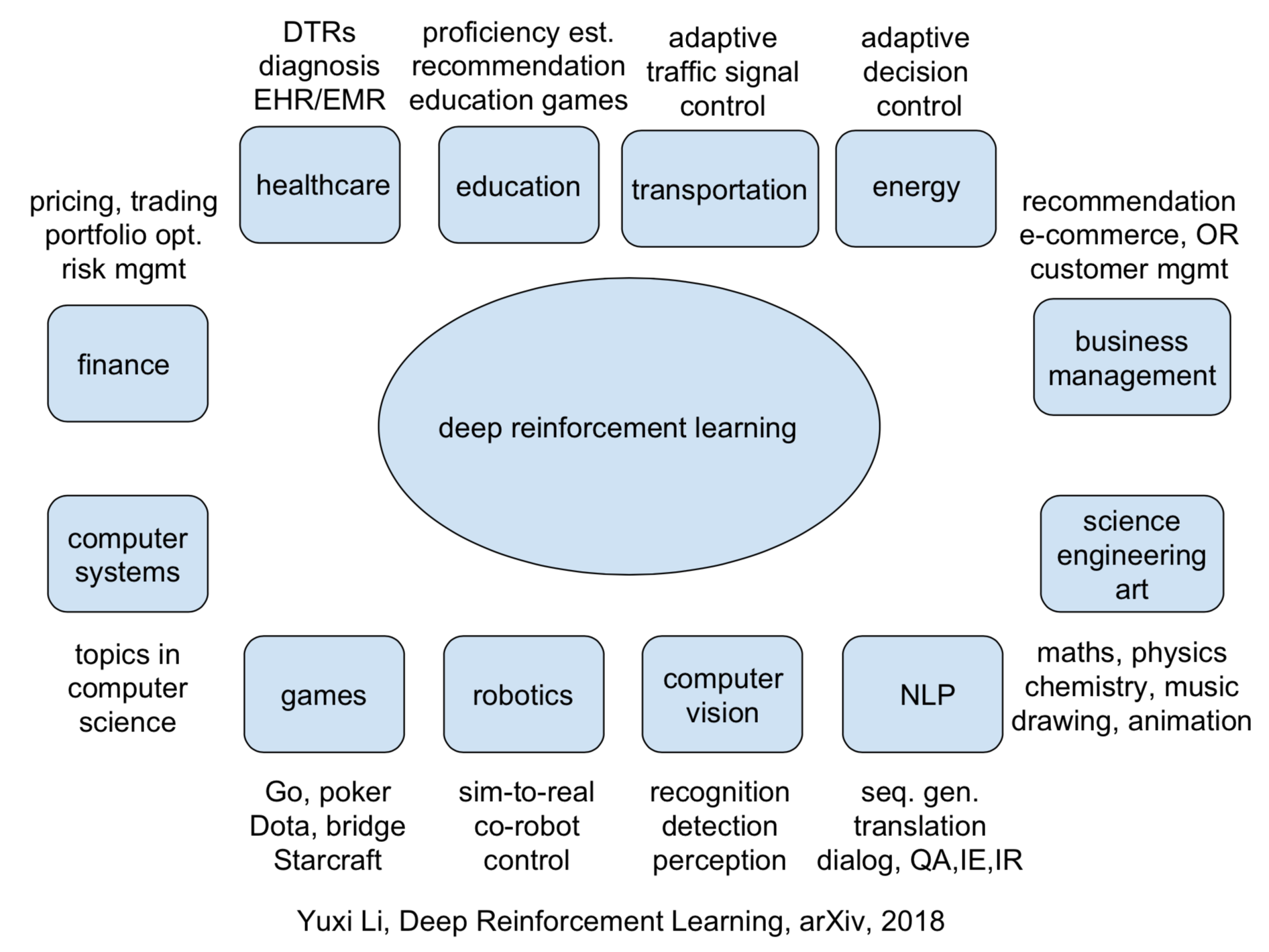
Reinforcement Learning Applications By Yuxi Li Medium

Reinforcement Learning For Control Systems Applications Matlab Simulink Mathworks Italia
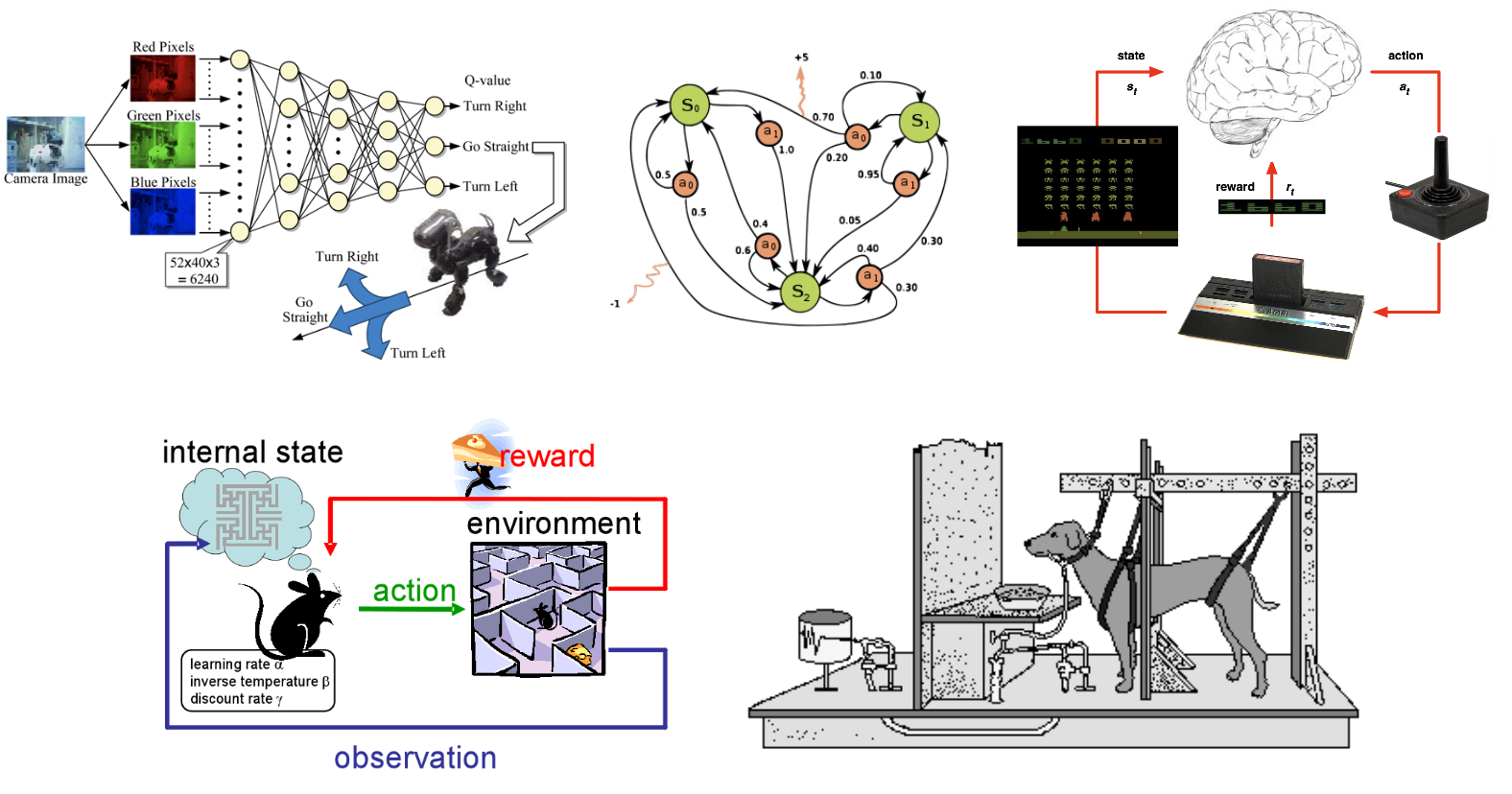
Comp 150 Reinforcement Learning

Training Procedure Of Policy Model Via Reinforcement Learning The Download Scientific Diagram
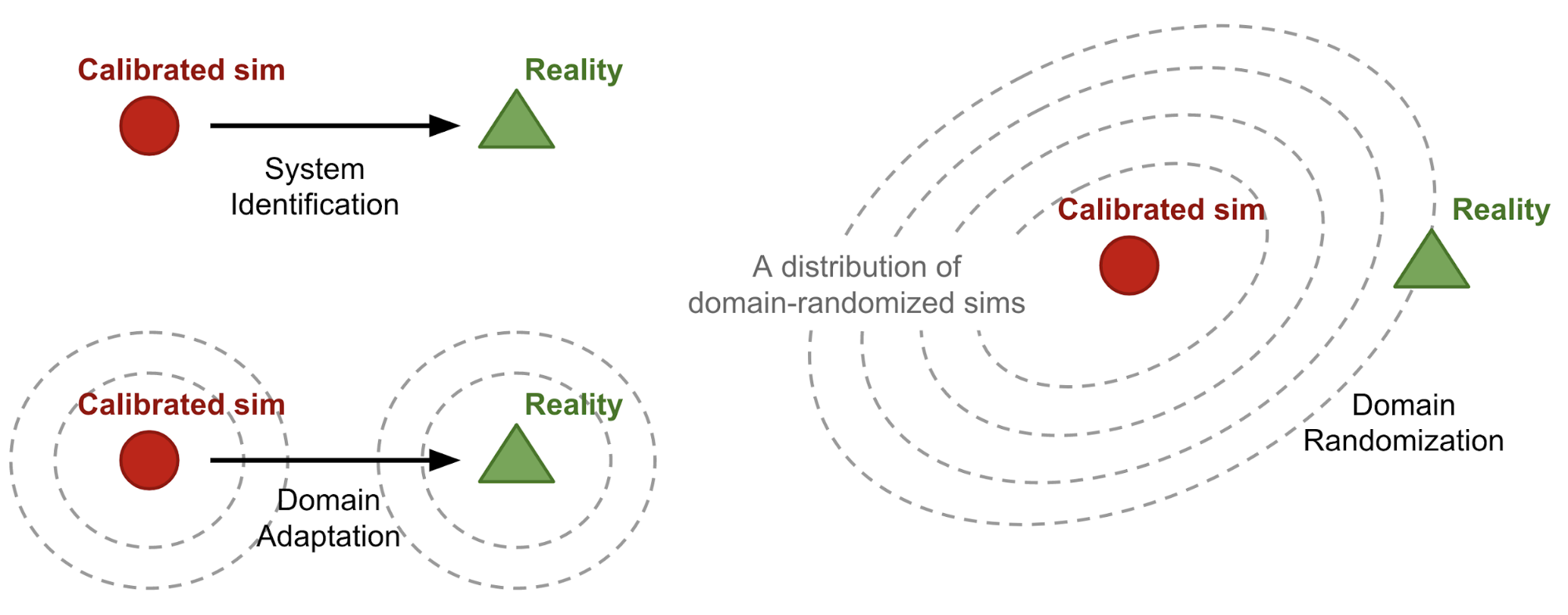
Domain Randomization For Sim2real Transfer
Aston university 14 share.
Domain adaptation reinforcement learning. Domain adaptation for reinforcement learning on the atari. Although reinforcement learning is known as an effective machine learning technique it might perform poorly in complex problems especially real world problems leading to a slow rate of convergence. Learning to transfer examples for partial domain adaptation. Deep reinforcement learning is a powerful machine learning paradigm that has had significant success across a wide range of control problems.
The proposed approach has the potential to solve a wide range of other domain adaptation problems in dqn based reinforcement learning potentially reducing the training cost for target domains although it can suffer from performance degradation in some cases possibly owing to inherent differences between the domains. Partial domain adaptation aims to transfer knowledge from a label rich source domain to a label scarce target domain which relaxes the fully shared label space assumption across different domains. Domain adaptation for reinforcement learning on the atari. Domain adversarial reinforcement learning for partial domain adaptation arxiv 10 may 2019 conference.
Partial adversarial domain adaptation pytorch official importance weighted adversarial nets for partial domain adaptation. To address this issue we. Uncertainty aware reinforcement learning from collision avoidance khan et al. 12 18 2018 by thomas carr et al.
2016 simple and scalable predictive uncertainty estimation using deep ensembles lakshminarayanan et al. However they can be slow to train and require a large number of interactions with the environment to learn a suitable policy. Associative domain adaptation haeusser et al. In this more general and practical scenario a major challenge is how to select source instances in the shared classes across different domains for positive transfer.
This issue magnifies when facing continuous domains where the curse of dimensionality is inevitable and generalization is mostly desired.

Machine Learning For Data Driven Discovery In Solid Earth Geoscience Science Machine Learning Data Science Data Driven

Cross Domain Transfer In Reinforcement Learning Using Target Apprentice Youtube
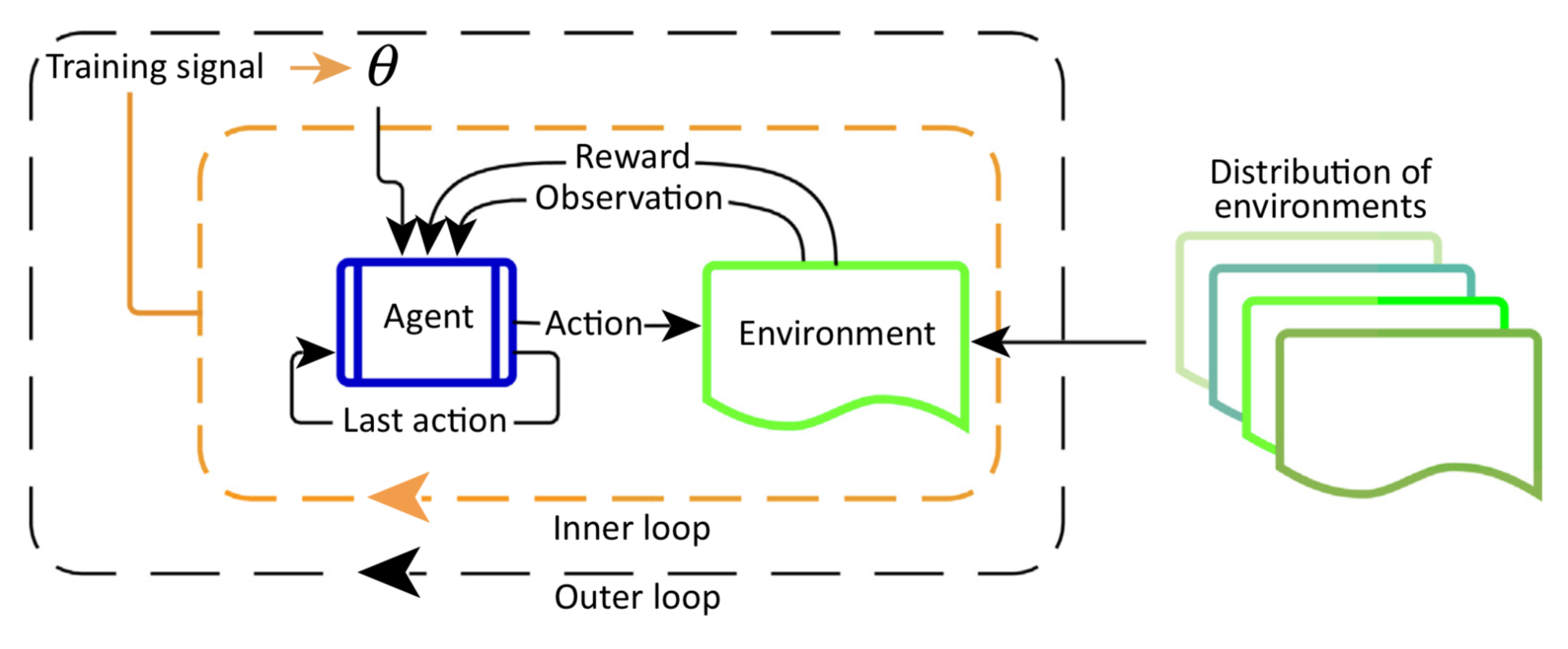
Meta Reinforcement Learning
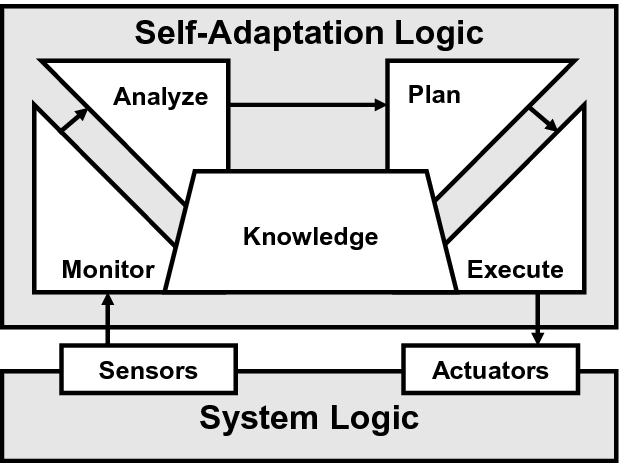
Online Reinforcement Learning For Self Adaptive Information Systems Springerlink

Machines That Morph Logic Neural Networks And The Distorted Automation Of Intelligence As Statistical Inference In 2020 Artificial Neural Network Logic Brain Models

A General Reinforcement Learning Algorithm That Masters Chess Shogi And Go Through Self Play Science Algorithm Play Science Chess

Nclex Course In Chandigarh Nclex Nursing License Nclex Exam
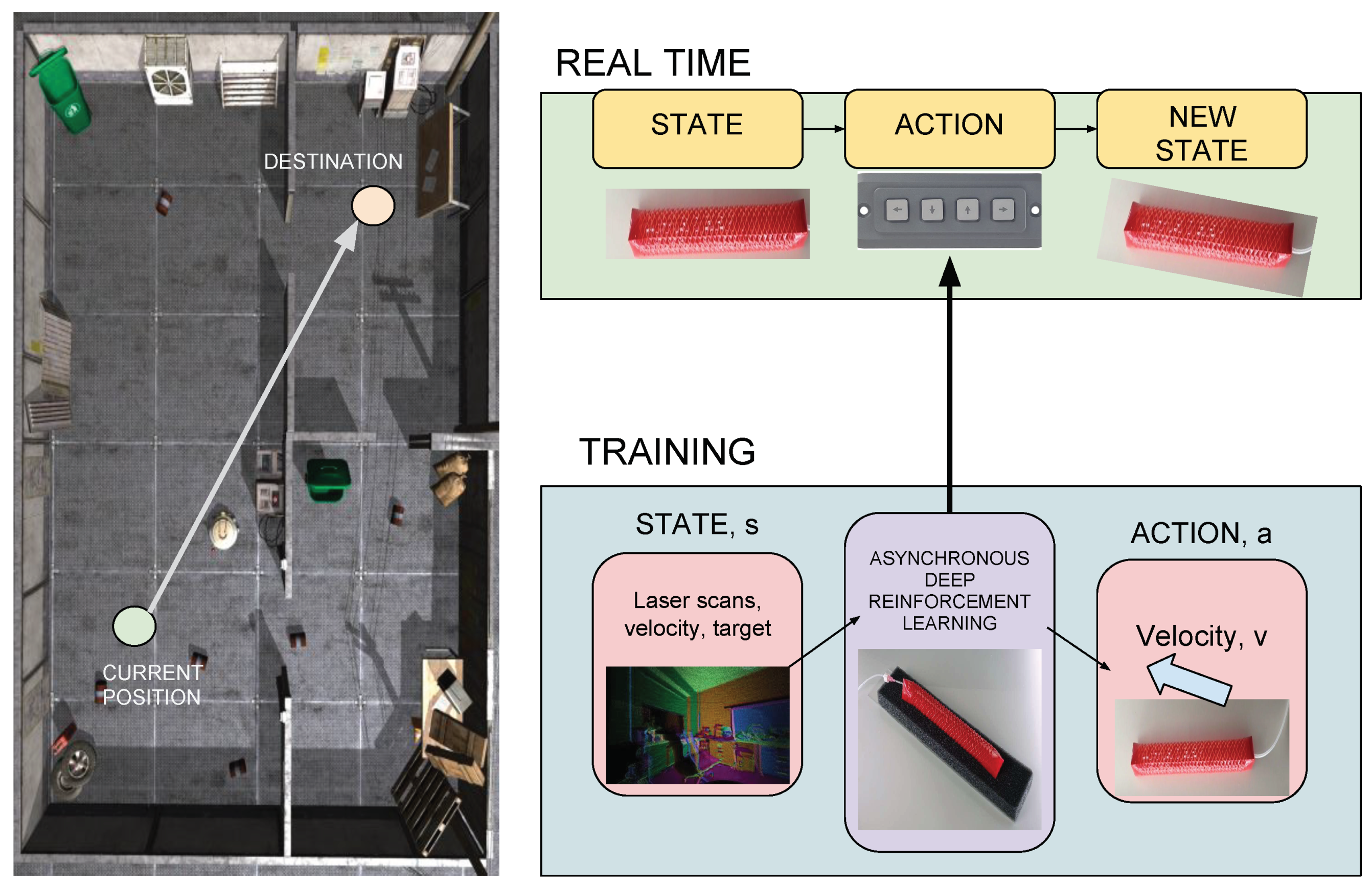
Robotics Free Full Text Deep Reinforcement Learning For Soft Flexible Robots Brief Review With Impending Challenges Html

Pdf Multi Agent Reinforcement Learning A Survey
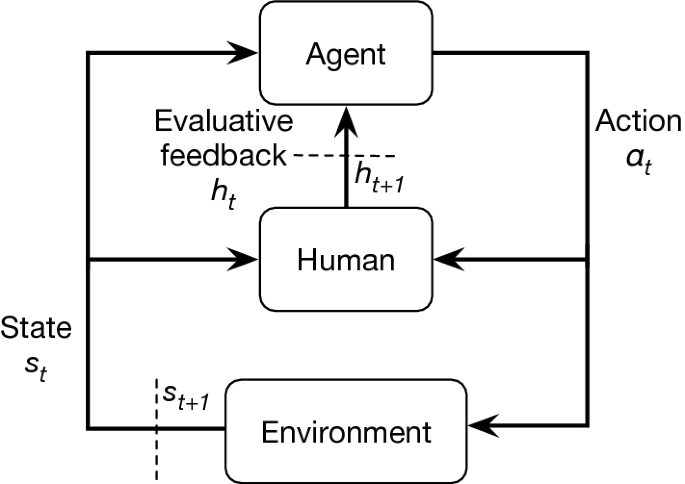
Facial Feedback For Reinforcement Learning A Case Study And Offline Analysis Using The Tamer Framework Springerlink
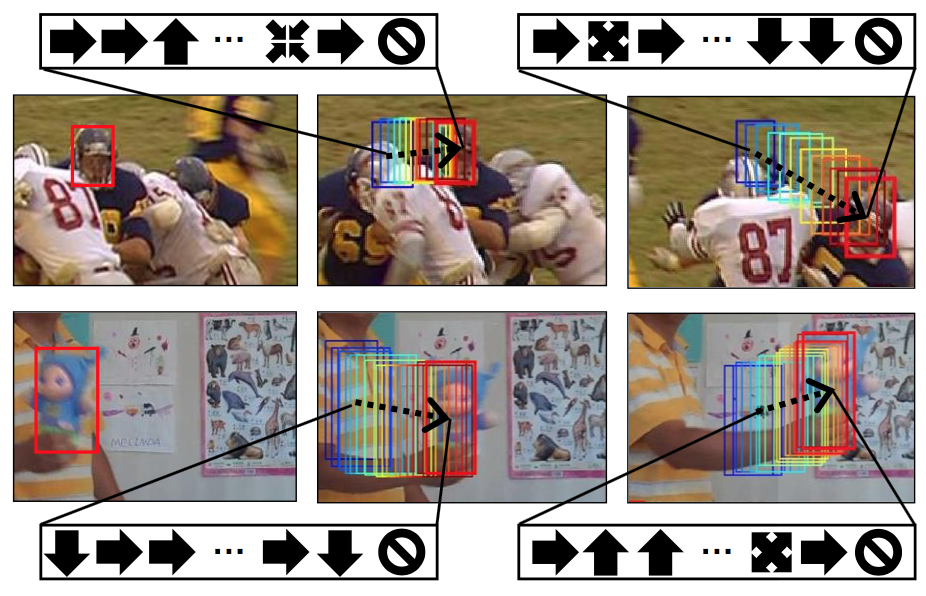
Adnet Action Based Object Tracking Using Reinforcement Learning Yehya Abouelnaga
Https Arxiv Org Pdf 2009 07888
